

Contents
- Architecture
- Control flow
- Modes Of Deployment
- Configuring Falcon
- Entity Management actions
- Instance Management actions
- Retention
- Replication
- Cross entity validations
- Updating cluster entity
- Updating process and feed definition
- Handling late input data
- Idempotency
- Falcon EL Expressions
- Lineage
- Security
- Extensions
- Monitoring
- Email Notification
- Backwards Compatibility Instructions
- Proxyuser support
- Data Import and Export
Introduction
Falcon is a feed and process management platform over hadoop. Falcon essentially transforms user's feed and process configurations into repeated actions through a standard workflow engine. Falcon by itself doesn't do any heavy lifting. All the functions and workflow state management requirements are delegated to the workflow scheduler. The only thing that Falcon maintains is the dependencies and relationship between these entities. This is adequate to provide integrated and seamless experience to the developers using the falcon platform.
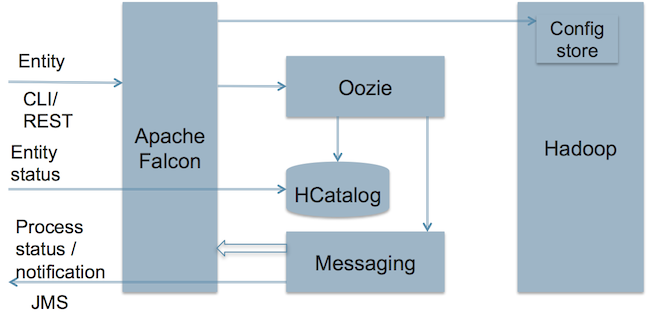
Scheduler
Falcon system has picked Oozie as the default scheduler. However the system is open for integration with other schedulers. Lot of the data processing in hadoop requires scheduling to be based on both data availability as well as time. Oozie currently supports these capabilities off the shelf and hence the choice.
While the use of Oozie works reasonably well, there are scenarios where Oozie scheduling is proving to be a limiting factor. In its current form, Falcon relies on Oozie for both scheduling and for workflow execution, due to which the scheduling is limited to time based/cron based scheduling with additional gating conditions on data availability. Also, this imposes restrictions on datasets being periodic/cyclic in nature. In order to offer better scheduling capabilities, Falcon comes with its own native scheduler. Refer to Falcon Native Scheduler for details.
Control flow
Though the actual responsibility of the workflow is with the scheduler (Oozie), Falcon remains in the execution path, by subscribing to messages that each of the workflow may generate. When Falcon generates a workflow in Oozie, it does so, after instrumenting the workflow with additional steps which includes messaging via JMS. Falcon system itself subscribes to these control messages and can perform actions such as retries, handling late input arrival etc.
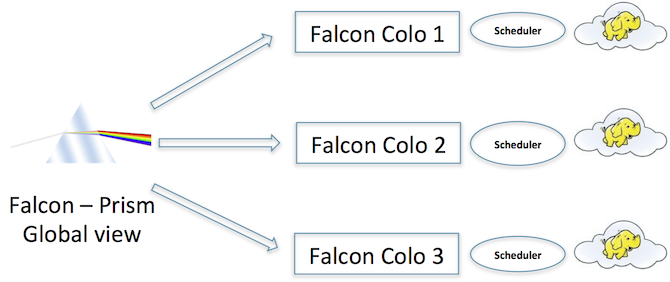
Modes Of Deployment
There are two basic components of Falcon set up. Falcon Prism and Falcon Server. As the name suggests Falcon Prism splits the request it gets to the Falcon Servers. More details below:
Stand Alone Mode
Stand alone mode is useful when the hadoop jobs and relevant data processing involves only one hadoop cluster. In this mode there is a single Falcon server that contacts Oozie to schedule jobs on Hadoop. All the process/feed requests like submit, schedule, suspend, kill etc. are sent to this server. For running falcon in this mode one should use the falcon which has been built using standalone option.
Distributed Mode
Distributed mode is for multiple (colos) instances of hadoop clusters, and multiple workflow schedulers to handle them. In this mode falcon has 2 components: Prism and Server(s). Both Prism and servers have their own setup (runtime and startup properties) and their own config locations. In this mode Prism acts as a contact point for Falcon servers. While all commands are available through Prism, only read and instance api's are available through Server. Below are the requests that can be sent to each of these:
Prism: submit, schedule, submitAndSchedule, Suspend, Resume, Kill, instance management Server: schedule, suspend, resume, instance management
As observed above submit and kill are kept exclusively as Prism operations to keep all the config stores in sync and to support feature of idempotency. Request may also be sent from prism but directed to a specific server using the option "-colo" from CLI or append the same in web request, if using API.
When a cluster is submitted it is by default sent to all the servers configured in the prism. When is feed is SUBMIT / SCHEDULED request is only sent to the servers specified in the feed / process definitions. Servers are mentioned in the feed / process via CLUSTER tags in xml definition.
Communication between prism and falcon server (for submit/update entity function) is secured over https:// using a client-certificate based auth. Prism server needs to present a valid client certificate for the falcon server to accept the action.
Startup property file in both falcon & prism server need to be configured with the following configuration if TLS is enabled. * keystore.file * keystore.password
Safe Mode
Safemode is useful when the admin wants to prevent Falcon users from scheduling entities in the workflow engine. This can happen when
- Hadoop clusters are being upgraded.
- Falcon cluster entities are being updated.
When in Safemode, users can only perform limited operations. To be specific,
- Users can perform read operations on entities subject to authorization.
- Superuser can perform cluster entity update operation.
- Suspend/Kill of individual instances will be allowed if users want to suspend specific job operations.
- Suspend operation on schedulable entities will be allowed. This is because, a user might want to suspend entities during rolling-upgrade to handle jobs incompatible with updated versions.
- All other operations are not allowed. To enumerate,
- All entity submit, submitAndSchedule operations are not allowed.
- Entity operations not allowed are : update, schedule, touch, delete, submit, submitAndSchedule, resume
- Instance operations not allowed are : rerun, resume
Getting into/out-of Safemode.
The Falcon process user can specify whether to start Falcon in safemode with the following command:
<falcon-server>/bin/falcon-start -setsafemode <true/false>
A superuser or admin-user can set Falcon server into/outof safemode using CLI or RestAPI. A user is considered superuser if they owns the Falcon process or belong to group specified in startup property falcon.security.authorization.superusergroup. A user is considered admin user if they are listed under startup property falcon.security.authorization.admin.users, OR they belong to group listed under startup property falcon.security.authorization.admin.groups.
## CLI <falcon-server>/bin/falcon admin [-setsafemode <true/false>] ## RestAPI GET http://falcon-server:15000/api/admin/setSafeMode/true OR GET http://falcon-server:15000/api/admin/setSafeMode/false
NOTE User can find if FalconServer is in safemode or not, by calling the Admin Version API. Once server is set to safemode, this state is persisted during restarts. It has to be unset explicitly if user wants to exit safemode.
Configuration Store
Configuration store is file system based store that the Falcon system maintains where the entity definitions are stored. File System used for the configuration store can either be a local file system or HDFS file system. It is recommended that the store be maintained outside of the system where Falcon is deployed. This is needed for handling issues relating to disk failures or other permanent failures of the system where Falcon is deployed. Configuration store also maintains an archive location where prior versions of the configuration or deleted configurations are maintained. They are never accessed by the Falcon system and they merely serve to track historical changes to the entity definitions.
Atomic Actions
Often times when Falcon performs entity management actions, it may need to do several individual actions. If one of the action were to fail, then the system could be in an inconsistent state. To avoid this, all individual operations performed are recorded into a transaction journal. This journal is then used to undo the overall user action. In some cases, it is not possible to undo the action. In such cases, Falcon attempts to keep the system in an consistent state.
Storage
Falcon introduces a new abstraction to encapsulate the storage for a given feed which can either be expressed as a path on the file system, File System Storage or a table in a catalog such as Hive, Catalog Storage.
<xs:choice minOccurs="1" maxOccurs="1">
<xs:element type="locations" name="locations"/>
<xs:element type="catalog-table" name="table"/>
</xs:choice>
Feed should contain one of the two storage options. Locations on File System or Table in a Catalog.
File System Storage
This is expressed as a location on the file system. Location specifies where the feed is available on this cluster. A location tag specifies the type of location like data, meta, stats and the corresponding paths for them. A feed should at least define the location for type data, which specifies the HDFS path pattern where the feed is generated periodically. ex: type="data" path="/projects/TrafficHourly/${YEAR}-${MONTH}-${DAY}/traffic" The granularity of date pattern in the path should be at least that of a frequency of a feed.
<location type="data" path="/projects/falcon/clicks" /> <location type="stats" path="/projects/falcon/clicksStats" /> <location type="meta" path="/projects/falcon/clicksMetaData" />
Catalog Storage (Table)
A table tag specifies the table URI in the catalog registry as:
catalog:$database-name:$table-name#partition-key=partition-value);partition-key=partition-value);*
This is modeled as a URI (similar to an ISBN URI). It does not have any reference to Hive or HCatalog. Its quite generic so it can be tied to other implementations of a catalog registry. The catalog implementation specified in the startup config provides implementation for the catalog URI.
Top-level partition has to be a dated pattern and the granularity of date pattern should be at least that of a frequency of a feed.
Examples:
<table uri="catalog:default:clicks#ds=${YEAR}-${MONTH}-${DAY}-${HOUR};region=${region}" />
<table uri="catalog:src_demo_db:customer_raw#ds=${YEAR}-${MONTH}-${DAY}-${HOUR}" />
<table uri="catalog:tgt_demo_db:customer_bcp#ds=${YEAR}-${MONTH}-${DAY}-${HOUR}" />
Configuring Falcon
Configuring Falcon is detailed in Configuration.
Entity Management actions
All the following operation can also be done using Falcon's RESTful API.
Submit
Entity submit action allows a new cluster/feed/process to be setup within Falcon. Submitted entity is not scheduled, meaning it would simply be in the configuration store within Falcon. Besides validating against the schema for the corresponding entity being added, the Falcon system would also perform inter-field validations within the configuration file and validations across dependent entities.
List
List all the entities within the falcon config store for the entity type being requested. This will include both scheduled and submitted entity configurations.
Dependency
Returns the dependencies of the requested entity. Dependency list include both forward and backward dependencies (depends on & is dependent on). For example, a feed would show process that are dependent on the feed and the clusters that it depends on.
Schedule
Feeds or Processes that are already submitted and present in the config store can be scheduled. Upon schedule, Falcon system wraps the required repeatable action as a bundle of oozie coordinators and executes them on the Oozie scheduler. (It is possible to extend Falcon to use an alternate workflow engine other than Oozie). Falcon overrides the workflow instance's external id in Oozie to reflect the process/feed and the nominal time. This external Id can then be used for instance management functions.
The schedule copies the user specified workflow and library to a staging path, and the scheduler references the workflow and lib from the staging path.
Suspend
This action is applicable only on scheduled entity. This triggers suspend on the oozie bundle that was scheduled earlier through the schedule function. No further instances are executed on a suspended process/feed.
Definition
Gets the current entity definition as stored in the configuration store. Please note that user documentations in the entity will not be retained.
Delete
Delete operation on the entity removes any scheduled activity on the workflow engine, besides removing the entity from the falcon configuration store. Delete operation on an entity would only succeed if there are no dependent entities on the deleted entity.
Update
Update operation allows an already submitted/scheduled entity to be updated. Feed update can cause cascading update to all the processes already scheduled. Process update triggers update in falcon if entity is scheduled.
Cluster update will require user to update dependent Feed and Process entities that are already scheduled. Cluster update needs to be performed in safemode. We provide a CLI command for the user to update the scheduled dependent entities after cluster update and exiting safemode.
The following set of actions are performed in scheduler to realize an update:
- Update the old scheduled entity to set the end time to "now"
- Schedule as per the new process/feed definition with the start time as "now"
Instance Management actions
Instance Manager gives user the option to control individual instances of the process based on their instance start time (start time of that instance). Start time needs to be given in standard TZ format. Example: 01 Jan 2012 01:00 => 2012-01-01T01:00Z
All the instance management operations (except running) allow single instance or list of instance within a Date range to be acted on. Make sure the dates are valid. i.e. are within the start and end time of process itself.
For every query in instance management the process name is a compulsory parameter.
Parameters -start and -end are used to mention the date range within which you want the instance to be operated upon.
-start: using only "-start" without "-end" will conduct the desired operation only on single instance given by date along with start.
-end: "-end" can only be used along with "-start" . It corresponds to the end date till which instance need to operated upon.
- 1. status: -status option via CLI can be used to get the status of a single or multiple instances. If the instance is not yet materialized but is within the process validity range, WAITING is returned as the state. Along with the status of the instance log location is also returned.
- 2. running: -running returns all the running instance of the process. It does not take any start or end dates but simply return all the instances in state RUNNING at that given time.
- 3. rerun: -rerun is the option that you will use most often from instance management. As the name suggest this option is used to rerun a particular instance or instances of the process. The rerun option reruns all parent workflow for the instance, which in turn rerun all the sub-workflows for it. This option is valid for any instance in terminal state, i.e. KILLED, SUCCEEDED, FAILED. User can also set properties in the request, which will give options what types of actions should be rerun like, only failed, run all etc. These properties are dependent on the workflow engine being used along with falcon.
- 4. suspend: -suspend is used to suspend a instance or instances for the given process. This option pauses the parent workflow at the state, which it was in at the time of execution of this command. This command is similar to SUSPEND process command in functionality only difference being, SUSPEND process suspends all the instance whereas suspend instance suspend only that instance or instances in the range.
- 5. resume: -resume option is used to resume any instance that is in suspended state. (Note: due to a bug in oozie �resume option in some cases may not actually resume the suspended instance/ instances)
- 6. kill: -kill option can be used to kill an instance or multiple instances
- 7. summary: -summary option via CLI can be used to get the consolidated status of the instances between the specified time period. Each status along with the corresponding instance count are listed for each of the applicable colos.
In all the cases where your request is syntactically correct but logically not, the instance / instances are returned with the same status as earlier. Example: trying to resume a KILLED / SUCCEEDED instance will return the instance with KILLED / SUCCEEDED, without actually performing any operation. This is so because only an instance in SUSPENDED state can be resumed. Same thing is valid for rerun a SUSPENDED or RUNNING options etc.
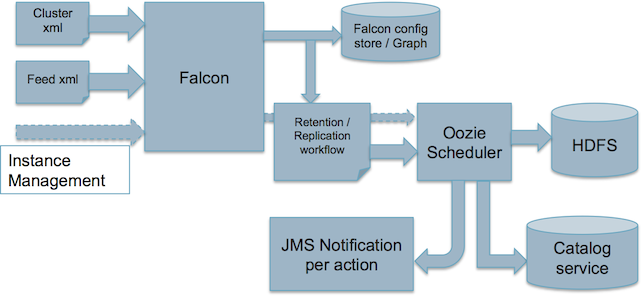
Retention
In coherence with it's feed lifecycle management philosophy, Falcon allows the user to retain data in the system for a specific period of time for a scheduled feed. The user can specify the retention period in the respective feed/data xml in the following manner for each cluster the feed can belong to :
<clusters>
<cluster name="corp" type="source">
<validity start="2012-01-30T00:00Z" end="2013-03-31T23:59Z"
timezone="UTC" />
<retention limit="hours(10)" action="delete" />
</cluster>
</clusters>
The 'limit' attribute can be specified in units of minutes/hours/days/months, and a corresponding numeric value can be attached to it. It essentially instructs the system to retain data till the time specified in the attribute spanning backwards in time, from now. Any data older than that is erased from the system. By default, Falcon runs retention jobs up to the cluster validity end time. This causes the instances created within the endTime and "endTime - retentionLimit" to be retained forever. If the users do not want to retain any instances of the feed past the cluster validity end time, user should set property "falcon.retention.keep.instances.beyond.validity" to false in runtime.properties.
With the integration of Hive, Falcon also provides retention for tables in Hive catalog.
When a feed is scheduled Falcon kicks off the retention policy immediately. When job runs, it deletes everything that's eligible for eviction - eligibility criteria is the date pattern on the partition and NOT creation date. For e.g. if the retention limit is 90 days then retention job consistently deletes files older than 90 days.
For retention, Falcon expects data to be in dated partitions. When the retention job is kicked off, it discovers data that needs to be evicted based on retention policy. It gets the location from the feed and uses pattern matching to find the pattern to get the list of data for the feed, then gets the date from the data path. If the data path date is beyond the retention limit it's deleted. As this uses pattern matching it is not time consuming and hence doesn't introduce performance overhead.
Example:
If retention period is 10 hours, and the policy kicks in at time 't', the data retained by system is essentially the one after or equal to t-10h . Any data before t-10h is removed from the system.
The 'action' attribute can attain values of DELETE/ARCHIVE. Based upon the tag value, the data eligible for removal is either deleted/archived.
When does retention policy come into play, aka when is retention really performed?
Retention policy in Falcon kicks off on the basis of the time value specified by the user. Here are the basic rules:
- If the retention policy specified is less than 24 hours: In this event, the retention policy automatically kicks off every 6 hours.
- If the retention policy specified is more than 24 hours: In this event, the retention policy automatically kicks off every 24 hours.
- As soon as a feed is successfully scheduled: the retention policy is triggered immediately regardless of the current timestamp/state of the system.
Relation between feed path and retention policy: Retention policy for a particular scheduled feed applies only to the eligible feed path specified in the feed xml. Any other paths that do not conform to the specified feed path are left unaffected by the retention policy.
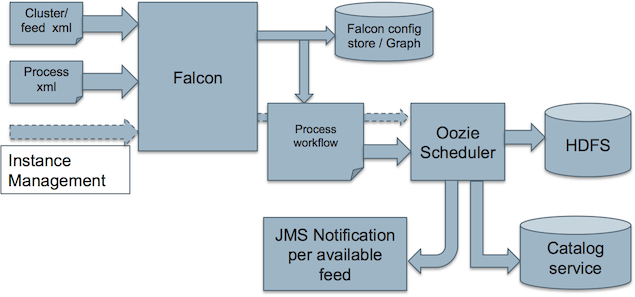
Replication
Falcon's feed lifecycle management also supports Feed replication across different clusters out-of-the-box. Multiple source clusters and target clusters can be defined in feed definition. Falcon replicates the data using hadoop's distcp version 2 across different clusters whenever a feed is scheduled.
The frequency at which the data is replicated is governed by the frequency specified in the feed definition. Ideally, the feeds data path should have the same granularity as that for frequency of the feed, i.e. if the frequency of the feed is hours(3), then the data path should be to level /${YEAR}/${MONTH}/${DAY}/${HOUR}.
<clusters>
<cluster name="sourceCluster1" type="source" partition="${cluster.name}" delay="minutes(40)">
<validity start="2021-11-01T00:00Z" end="2021-12-31T00:00Z"/>
</cluster>
<cluster name="sourceCluster2" type="source" partition="COUNTRY/${cluster.name}">
<validity start="2021-11-01T00:00Z" end="2021-12-31T00:00Z"/>
</cluster>
<cluster name="backupCluster" type="target">
<validity start="2011-11-01T00:00Z" end="2011-12-31T00:00Z"/>
</cluster>
</clusters>
If more than 1 source cluster is defined, then partition expression is compulsory, a partition can also have a constant. The expression is required to avoid copying data from different source location to the same target location, also only the data in the partition is considered for replication if it is present. The partitions defined in the cluster should be less than or equal to the number of partition declared in the feed definition.
Falcon uses pull based replication mechanism, meaning in every target cluster, for a given source cluster, a coordinator is scheduled which pulls the data using distcp from source cluster. So in the above example, 2 coordinators are scheduled in backupCluster, one which pulls the data from sourceCluster1 and another from sourceCluster2. Also, for every feed instance which is replicated Falcon sends a JMS message on success or failure of replication instance.
Replication can be scheduled with the past date, the time frame considered for replication is the minimum overlapping window of start and end time of source and target cluster, ex: if s1 and e1 is the start and end time of source cluster respectively, and s2 and e2 of target cluster, then the coordinator is scheduled in target cluster with start time max(s1,s2) and min(e1,e2).
A feed can also optionally specify the delay for replication instance in the cluster tag, the delay governs the replication instance delays. If the frequency of the feed is hours(2) and delay is hours(1), then the replication instance will run every 2 hours and replicates data with an offset of 1 hour, i.e. at 09:00 UTC, feed instance which is eligible for replication is 08:00; and 11:00 UTC, feed instance of 10:00 UTC is eligible and so on.
If it is required to capture the feed replication metrics like TIMETAKEN, COPY, BYTESCOPIED, set the parameter "job.counter" to "true" in feed entity properties section. Captured metrics from instance will be populated to the GraphDB for display on UI.
Example:
<properties>
<property name="job.counter" value="true" />
</properties>
Where is the feed path defined for File System Storage?
It's defined in the feed xml within the location tag.
Example:
<locations>
<location type="data" path="/retention/testFolders/${YEAR}-${MONTH}-${DAY}" />
</locations>
Now, if the above path contains folders in the following fashion:
/retention/testFolders/${YEAR}-${MONTH}-${DAY} /retention/testFolders/${YEAR}-${MONTH}/someFolder
The feed retention policy would only act on the former and not the latter.
Users may choose to override the feed path specific to a cluster, so every cluster may have a different feed path. Example:
<clusters>
<cluster name="testCluster" type="source">
<validity start="2011-11-01T00:00Z" end="2011-12-31T00:00Z"/>
<locations>
<location type="data" path="/projects/falcon/clicks/${YEAR}-${MONTH}-${DAY}" />
<location type="stats" path="/projects/falcon/clicksStats/${YEAR}-${MONTH}-${DAY}" />
<location type="meta" path="/projects/falcon/clicksMetaData/${YEAR}-${MONTH}-${DAY}" />
</locations>
</cluster>
</clusters>
Hive Table Replication
With the integration of Hive, Falcon adds table replication of Hive catalog tables. Replication will be triggered for a partition when the partition is complete at the source.
- Falcon will use HCatalog (Hive) API to export the data for a given table and the partition,
- Falcon will use discp tool to copy the exported data collection into the secondary cluster into a staging
- Falcon will then import the data into HCatalog (Hive) using the HCatalog (Hive) API. If the specified table does
- The partition is not complete and hence not visible to users until all the data is committed on the secondary
Archival as Replication
Falcon allows users to archive data from on-premise to cloud, either Azure WASB or S3. It uses the underlying replication for archiving data from source to target. The archival URI is specified as the overridden location for the target cluster. Note that for data replication between on-premise and Azure cloud, Azure credentials need to be added to core-site.xml. Please refer to AzureDataReplication for details and examples.
Example:
<clusters>
<cluster name="on-premise-cluster" type="source">
<validity start="2021-11-01T00:00Z" end="2021-12-31T00:00Z"/>
</cluster>
<cluster name="cloud-cluster" type="target">
<validity start="2011-11-01T00:00Z" end="2011-12-31T00:00Z"/>
<locations>
<location type="data"
path="wasb://test@blah.blob.core.windows.net/data/${YEAR}-${MONTH}-${DAY}-${HOUR}"/>
</locations>
</cluster>
</clusters>
Relation between feed's retention limit and feed's late arrival cut off period:
For reasons that are obvious, Falcon has an external validation that ensures that the user always specifies the feed retention limit to be more than the feed's allowed late arrival period. If this rule is violated by the user, the feed submission call itself throws back an error.
Entity Dependencies in a nutshell
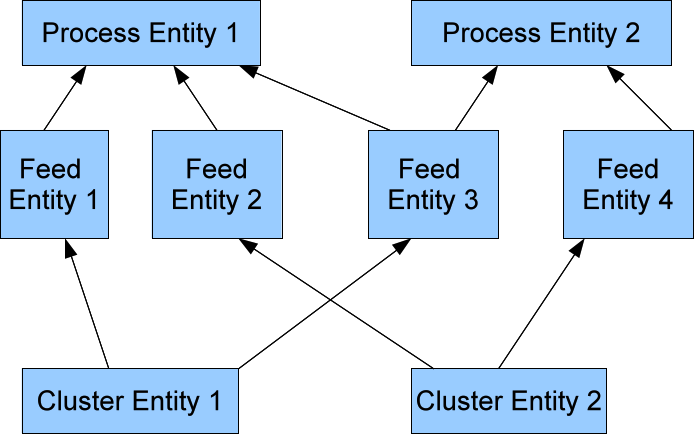
The above schematic shows the dependencies between entities in Falcon. The arrow in above diagram points from a dependency to the dependent.
Let's just get one simple rule stated here, which we will keep referring to time and again while talking about entities: A dependency in the system cannot be removed unless all it's dependents are removed first. This holds true for all transitive dependencies also.
Now, let's follow it up with a simple illustration of an Falcon Job:
Let's consider a process P that refers to feed F1 as an input feed, and generates feed F2 as an output feed. These feeds/processes are supposed to be associated with a cluster C1.
The order of submission of this job would be in the following order:
C1->F1/F2(in any order)->P
The order of removal of this job from the system is in the exact opposite order, i.e.:
P->F1/F2(in any order)->C1
Please note that there might be multiple process referring to a particular feed, or a single feed belonging to multiple clusters. In that event, any of the dependencies cannot be removed unless ALL of their dependents are removed first. Attempting to do so will result in an error message and a 400 Bad Request operation.
Other cross validations between entities in Falcon system
Cluster-Feed Cross validations:
- The cluster(s) referenced by feed (inside the <clusters> tag) should be present in the system at the time
Example:
Feed XML:
<clusters>
<cluster name="corp" type="source">
<validity start="2009-01-01T00:00Z" end="2012-12-31T23:59Z"
timezone="UTC" />
<retention limit="months(6)" action="delete" />
</cluster>
</clusters>
Cluster corp's XML:
<cluster colo="gs" description="" name="corp" xmlns="uri:falcon:cluster:0.1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
Cluster-Process Cross validations:
- In a similar relationship to that of feed and a cluster, a process also refers to the relevant cluster by the
Cluster corp's XML:
<cluster colo="gs" description="" name="corp" xmlns="uri:falcon:cluster:0.1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
Feed-Process Cross Validations:
1. The process <input> and feeds designated as input feeds for the job:
For every feed referenced in the <input> tag in a process definition, following rules are applied when the process is due for submission:
- The feed having a value associated with the 'feed' attribute in input tag should be present in
Example:
Process xml:
<input end-instance="now(0,20)" start-instance="now(0,-60)" feed="raaw-logs16" name="inputData"/>
Feed xml:
<feed description="clicks log" name="raw-logs16"....
* The time interpretation for corresponding tags indicating the start and end instances for a particular input feed in the process xml should lie well within the time span of the period specified in <validity> tag of the particular feed.
Example:
1. In the following scenario, process submission will result in an error:
Process XML:
<input end-instance="now(0,20)" start-instance="now(0,-60)" feed="raw-logs16" name="inputData"/>
Feed XML:
<validity start="2009-01-01T00:00Z" end="2009-12-31T23:59Z".....
Explanation: The process timelines for the feed range between a 40 minute interval between [-60m,-20m] from the current timestamp (which lets assume is 'today' as per the 'now' directive). However, the feed validity is between a 1 year period in 2009, which makes it anachronistic.
2. The following example would work just fine:
Process XML:
<input end-instance="now(0,20)" start-instance="now(0,-60)" feed="raaw-logs16" name="inputData"/>
Feed XML:
validity start="2009-01-01T00:00Z" end="2012-12-31T23:59Z" .......
since at the time of charting this document (03/03/2012), the feed validity is able to encapsulate the process input's start and end instances.
Failure to follow any of the above rules would result in a process submission failure.
NOTE: Even though the above check ensures that the timelines are not anachronistic, if the input data is not present in the system for the specified time period, the process can be submitted and scheduled, but all instances created would result in a WAITING state unless data is actually provided in the cluster.
Updating cluster entity definition
Cluster entities can be updated when the user wants to change their interface endpoints or properties, e.g. hadoop clusters updated from unsecure to secure; hadoop cluster moved from non high-availability to high-availability, etc.
In these scenarios, user would want to change the cluster entity to reflect updated interface endpoints or properties. Updating cluster would require cascading update to dependent feed/process jobs scheduled on this cluster. So Falcon only allows Cluster update when
- Falcon server is in safemode.
- The update is requested by superuser
- The underlying namenode or workflow engine referenced by interface URI is the same. It is only the URI that has changed to reflect secure/HA environments.
Cluster entity should be updated by superuser using following CLI command.
bash$ falcon entity -type cluster -name primaryCluster -update -file ~/primary-updated.xml
Once the cluster entity is updated, user should exit FalconServer from safemode and update the scheduled entities that are dependent on this Cluster. In case of an error during update, user should address the root cause of failure and retry the command. For example : if the cluster has 10 dependent entities and the updateClusterDependents command failed after updating 6th entity, rerun of this command will only update entities 7 to 10.
bash$ falcon entity -updateClusterDependents -cluster primaryCluster
Please Refer to Falcon CLI for more details on usage of CLI commands.
Updating process and feed definition
Any changes in feed/process can be done by updating its definition. After the update, any new workflows which are to be scheduled after the update call will pick up the new changes. Feed/process name and start time can't be updated. Updating a process triggers updates to the workflow that is triggered in the workflow engine. Updating feed updates feed workflows like retention, replication etc. and also updates the processes that reference the feed.
Handling late input data
Falcon system can handle late arrival of input data and appropriately re-trigger processing for the affected instance. From the perspective of late handling, there are two main configuration parameters late-arrival cut-off and late-inputs section in feed and process entity definition that are central. These configurations govern how and when the late processing happens. In the current implementation (oozie based) the late handling is very simple and basic. The falcon system looks at all dependent input feeds for a process and computes the max late cut-off period. Then it uses a scheduled messaging framework, like the one available in Apache ActiveMQ or Java's DelayQueue to schedule a message with a cut-off period, then after a cut-off period the message is dequeued and Falcon checks for changes in the feed data which is recorded in HDFS in latedata file by falcons "record-size" action, if it detects any changes then the workflow will be rerun with the new set of feed data.
Example: For a process entity, the late rerun policy can be configured in the process definition. Falcon supports 3 policies, periodic, exp-backoff and final. Delay specifies, how often the feed data should be checked for changes, also one needs to explicitly set the feed names in late-input which needs to be checked for late data.
<late-process policy="exp-backoff" delay="hours(1)">
<late-input input="impression" workflow-path="hdfs://impression/late/workflow" />
<late-input input="clicks" workflow-path="hdfs://clicks/late/workflow" />
</late-process>
NOTE: Feeds configured with table storage does not support late input data handling at this point. This will be made available in the near future.
For a feed entity replication job, the default late data handling policy can be configured in the runtime.properties file. Since these properties are runtime.properties, they will take effect for all replication jobs completed subsequent to the change.
# Default configs to handle replication for late arriving feeds. *.feed.late.allowed=true *.feed.late.frequency=hours(3) *.feed.late.policy=exp-backoff
Idempotency
All the operations in Falcon are Idempotent. That is if you make same request to the falcon server / prism again you will get a SUCCESSFUL return if it was SUCCESSFUL in the first attempt. For example, you submit a new process / feed and get SUCCESSFUL message return. Now if you run the same command / api request on same entity you will again get a SUCCESSFUL message. Same is true for other operations like schedule, kill, suspend and resume. Idempotency also by takes care of the condition when request is sent through prism and fails on one or more servers. For example prism is configured to send request to 3 servers. First user sends a request to SUBMIT a process on all 3 of them, and receives a response SUCCESSFUL from all of them. Then due to some issue one of the servers goes down, and user send a request to schedule the submitted process. This time he will receive a response with PARTIAL status and a FAILURE message from the server that has gone down. If the users check he will find the process would have been started and running on the 2 SUCCESSFUL servers. Now the issue with server is figured out and it is brought up. Sending the SCHEDULE request again through prism will result in a SUCCESSFUL response from prism as well as other three servers, but this time PROCESS will be SCHEDULED only on the server which had failed earlier and other two will keep running as before.
Falcon EL Expressions
Falcon expression language can be used in process definition for giving the start and end instance for various feeds.
Before going into how to use falcon EL expressions it is necessary to understand what does instance and instance start time refer to with respect to Falcon.
Lets consider a part of process definition below:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<process name="testProcess">
<clusters>
<cluster name="corp">
<validity start="2010-01-02T01:00Z" end="2011-01-03T03:00Z" />
</cluster>
</clusters>
<parallel>2</parallel>
<order>LIFO</order>
<timeout>hours(3)</timeout>
<frequency>minutes(30)</frequency>
<inputs>
<input end-instance="now(0,20)" start-instance="now(0,-60)"
feed="input-log" name="inputData"/>
</inputs>
<outputs>
<output instance="now(0,0)" feed="output-log"
name="outputData" />
</outputs>
...
...
...
...
</process>
The above definition says that the process will start at 2nd of Jan 2010 at 1 am and will end at 3rd of Jan 2011 at 3 am on cluster corp. Also process will start a user-defined workflow (which we will call instance) every 30 mins.
This means starting 2010-01-02T01:00Z every 30 mins a instance will start will run user defined workflow. Now if this workflow needs some input data and produce some output, user needs to give that in <inputs> and <outputs> tags. Since the inputs that the process takes can be distributed over a wide range we use the limits by giving "start" and "end" instance for input. Output is only one location so only instance is given. The timeout specifies, the how long a given instance should wait for input data before being terminated by the workflow engine.
Coming back to instance start time, since a instance will start every 30 mins starting 2010-01-02T01:00Z, the time it is scheduled to start is called its instance time. For example first few instance time for above example are:
Instance Number instance start Time
1 2010-01-02T01:00Z
2 2010-01-02T01:30Z
3 2010-01-02T02:00Z
4 2010-01-02T02:30Z
. .
. .
. .
. .
Now lets go to how to use expression language. Only thing to keep in mind is all EL evaluation are done based on the start time of that instance, and very instance will have different inputs / outputs based on the feed instance given in process definition.
All the parameters in various El can be both positive, zero or negative values. Positive values indicate so many units in future, zero means the base time EL has been resolved to, and negative values indicate corresponding units in past.
Note: if no instance is created at the resolved time, then the instance immediately before it is considered.
Falcon currently support following ELs:
- 1. now(hours,minutes): now refer to the instance start time. Hours and minutes given are in reference with the start time of instance. For example now(-2,40) corresponds to feed instance at -2 hr and +40 minutes i.e. feed instance 80 mins before the instance start time. Id user would have given now(0,-80) it would have correspond to the same.
- 2. today(hours,minutes): hours and minutes given in this EL corresponds to instance from the start day of instance start time. Ie. If instance start is at 2010-01-02T01:30Z then today(-3,-20) will mean instance created at 2010-01-01T20:40 and today(3,20) will correspond to 2010-01-02T3:20Z.
- 3. yesterday(hours,minutes): As the name suggest EL yesterday picks up feed instances with respect to start of day yesterday. Hours and minutes are added to the 00 hours starting yesterday, Example: yesterday(24,30) will actually correspond to 00:30 am of today, for 2010-01-02T01:30Z this would mean 2010-01-02:00:30 feed.
- 7. lastYear(month,day,hour,minute): This is exactly similarly to currentYear in usage> only difference being start reference is taken to start of previous year. For example: lastYear(4,2,2,20) will correspond to feed instance created at 2009-05-03T02:20Z and lastYear(12,2,2,20) will correspond to feed at 2010-01-03T02:20Z.
- 4. currentMonth(day,hour,minute): Current month takes the reference to start of the month with respect to instance start time. One thing to keep in mind is that day is added to the first day of the month. So the value of day is the number of days you want to add to the first day of the month. For example: for instance start time 2010-01-12T01:30Z and El as currentMonth(3,2,40) will correspond to feed created at 2010-01-04T02:40Z and currentMonth(0,0,0) will mean 2010-01-01T00:00Z.
- 5. lastMonth(day,hour,minute): Parameters for lastMonth is same as currentMonth, only difference being the reference is shifted to one month back. For instance start 2010-01-12T01:30Z lastMonth(2,3,30) will correspond to feed instance at 2009-12-03:T03:30Z
- 6. currentYear(month,day,hour,minute): The month,day,hour, minutes in the parameter are added with reference to the start of year of instance start time. For our example start time 2010-01-02:00:30 reference will go back to 2010-01-01:T00:00Z. Also similar to days, months are added to the 1st month that Jan. So currentYear(0,2,2,20) will mean 2010-01-03T02:20Z while currentYear(11,2,2,20) will mean 2010-12-03T02:20Z
- 7. lastYear(month,day,hour,minute): This is exactly similarly to currentYear in usage> only difference being start reference is taken to start of previous year. For example: lastYear(4,2,2,20) will corrospond to feed insatnce created at 2009-05-03T02:20Z and lastYear(12,2,2,20) will corrospond to feed at 2010-01-03T02:20Z.
- 8. latest(number of latest instance): This will simply make you input consider the number of latest available instance of the feed given as parameter. For example: latest(0) will consider the last available instance of feed, where as latest latest(-1) will consider second last available feed and latest(-3) will consider 4th last available feed.
- 9. currentWeek(weekDayName,hour,minute): This is similar to currentMonth in the sense that it returns a relative time with respect to the instance start time, considering the day name provided as input as the start of the week. The day names can be one of SUN, MON, TUE, WED, THU, FRI, SAT.
- 10. lastWeek(weekDayName,hour,minute): This is typically 7 days less than what the currentWeek returns for similar parameters.
Lineage
Falcon adds the ability to capture lineage for both entities and its associated instances. It also captures the metadata tags associated with each of the entities as relationships. The following relationships are captured:
- owner of entities - User
- data classification tags
- groups defined in feeds
- Relationships between entities
- Clusters associated with Feed and Process entity
- Input and Output feeds for a Process
- Instances refer to corresponding entities
Lineage is exposed in 3 ways:
- REST API
- CLI
- Dashboard - Interactive lineage for Process instances
This feature is enabled by default but could be disabled by removing the following from:
config name: *.application.services config value: org.apache.falcon.metadata.MetadataMappingService
Lineage is only captured for Process executions. A future release will capture lineage for lifecycle policies such as replication and retention.
Security
Security is detailed in Security.
Extensions
Extensions is detailed in Extensions.
Monitoring
Monitoring and Operationalizing Falcon is detailed in Operability and Falcon Feed SLA Monitoring.
Email Notification
Notification for instance completion in Falcon is defined in Falcon Email Notification.
Backwards Compatibility
Backwards compatibility instructions are detailed here.
Proxyuser support
Falcon supports impersonation or proxyuser functionality (identical to Hadoop proxyuser capabilities and conceptually similar to Unix 'sudo').
Proxyuser enables Falcon clients to submit entities on behalf of other users. Falcon will utilize Hadoop core's hadoop-auth module to implement this functionality.
Because proxyuser is a powerful capability, Falcon provides the following restriction capabilities (similar to Hadoop):
- Proxyuser is an explicit configuration on per proxyuser user basis.
- A proxyuser user can be restricted to impersonate other users from a set of hosts.
- A proxyuser user can be restricted to impersonate users belonging to a set of groups.
There are 2 configuration properties needed in runtime properties to set up a proxyuser:
- falcon.service.ProxyUserService.proxyuser.#USER#.hosts: hosts from where the user #USER# can impersonate other users.
- falcon.service.ProxyUserService.proxyuser.#USER#.groups: groups the users being impersonated by user #USER# must belong to.
If these configurations are not present, impersonation will not be allowed and connection will fail. If more lax security is preferred, the wildcard value * may be used to allow impersonation from any host or of any user, although this is recommended only for testing/development.
-doAs option via CLI or doAs query parameter can be appended if using API to enable impersonation.
ImportExport
Data Import and Export is detailed in Data Import and Export.